Entdecken Sie in diesem Artikel, wie ein Huffman-Decoder funktioniert, seine Anwendungen, Herausforderungen und seine Rolle in der Datenkompression.
Was ist ein Huffman-Decoder?
Ein Huffman-Decoder ist ein wesentlicher Bestandteil der Datenkompression, insbesondere in der Huffman-Kodierung, einem weit verbreiteten Algorithmus zur verlustfreien Datenkompression. Die Huffman-Kodierung nutzt die unterschiedlichen Häufigkeiten von Daten, um eine effiziente Codierungsmethode zu erstellen, wobei häufiger vorkommende Daten mit kürzeren Codes und seltener vorkommende Daten mit längeren Codes versehen werden. Ein Huffman-Decoder ist das Werkzeug, das diese speziellen Codierungen wieder in ihre ursprüngliche Form zurückübersetzt.
Wie funktioniert ein Huffman-Decoder?
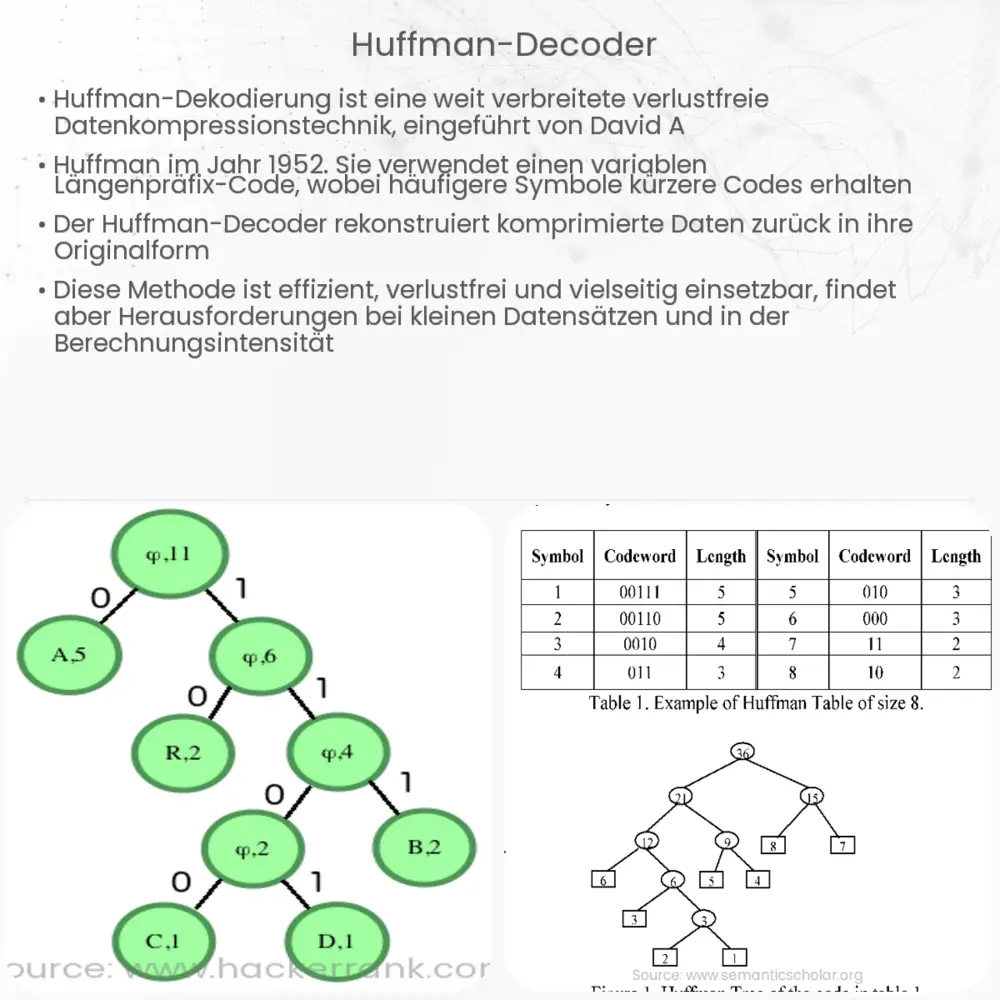
Der Prozess des Huffman-Decodings beginnt mit einem Huffman-Baum, der während des Kompressionsprozesses erstellt wird. Dieser Baum repräsentiert die Codierungen der verschiedenen Daten oder Zeichen in einer hierarchischen Struktur. Beim Decodieren durchläuft der Decoder den Baum von der Wurzel bis zu den Blättern, basierend auf der Sequenz der codierten Daten. Jedes Blatt des Baumes entspricht einem Zeichen der ursprünglichen Daten.
Beispielsweise könnte in einer einfachen Huffman-Kodierung der Buchstabe ‚E‘, der am häufigsten in einem Text vorkommt, durch den kürzesten Code, sagen wir ‚0‘, dargestellt werden. Weniger häufige Buchstaben wie ‚Z‘ könnten durch längere Codes wie ‚1011‘ dargestellt werden. Der Huffman-Decoder liest die codierte Nachricht und folgt dem Pfad des Huffman-Baumes, um jeden Code in sein entsprechendes Zeichen zu übersetzen.
Anwendungen des Huffman-Decoders
Huffman-Decoding wird in vielen digitalen Systemen zur Datenreduktion eingesetzt. Dazu gehören Textdateien, Bild- und Videokompression und sogar in der Datenübertragung, um die Effizienz zu steigern und Speicherplatz zu sparen. Es ist besonders nützlich in Situationen, in denen die verlustfreie Wiederherstellung von Daten wichtig ist, wie z.B. in der medizinischen Bildgebung oder bei der Archivierung wichtiger Dokumente.
Die Effizienz der Huffman-Kodierung und damit des Decoders hängt stark von der Verteilung der Häufigkeit der Daten ab. In Fällen, in denen einige Daten sehr häufig und andere sehr selten sind, kann die Huffman-Kodierung deutlich effizienter sein als andere Kodierungsmethoden.
Der Prozess des Huffman-Decodings
Der Huffman-Decoder beginnt seine Arbeit, indem er die binäre Sequenz liest, die während der Kompression generiert wurde. Für jedes Bit in der Sequenz folgt der Decoder dem entsprechenden Pfad im Huffman-Baum: ‚0‘ führt in der Regel zum linken Kindknoten, während ‚1‘ zum rechten Kindknoten führt. Erreicht der Decoder ein Blatt des Baumes, wird das entsprechende Zeichen decodiert und der Prozess beginnt erneut von der Wurzel des Baumes für die nächsten Bits der Sequenz.
Dieser Vorgang setzt sich fort, bis die gesamte binäre Sequenz abgearbeitet ist und die ursprünglichen Daten vollständig rekonstruiert sind. Der Schlüssel für die erfolgreiche Dekompression liegt in der korrekten Rekonstruktion des Huffman-Baumes, der während der Kompressionsphase verwendet wurde. Ohne diesen Baum ist die decodierte Information unverständlich.
Herausforderungen und Grenzen
Trotz seiner Effizienz in vielen Anwendungsfällen hat die Huffman-Kodierung auch ihre Grenzen. Bei Daten, die eine gleichmäßige Verteilung ohne deutliche Häufigkeitsunterschiede aufweisen, bietet die Huffman-Kodierung möglicherweise keine signifikante Kompressionsrate. Ebenso ist die Huffman-Kodierung nicht geeignet für Datenkompression, bei der eine verlustbehaftete Reduktion akzeptabel ist – ein Bereich, in dem andere Algorithmen wie JPEG für Bilder oder MP3 für Audiodaten besser geeignet sind.
Ein weiteres Problem kann die Notwendigkeit der Übertragung des Huffman-Baumes zusammen mit den komprimierten Daten sein, was zusätzlichen Speicherplatz beansprucht. Für kleine Datenmengen oder Daten mit vielen verschiedenen Zeichen kann der zusätzliche Speicherplatzbedarf für den Baum die Einsparungen durch die Kompression teilweise oder ganz aufheben.
Fazit
Der Huffman-Decoder spielt eine entscheidende Rolle in der Welt der Datenkompression. Durch die Rückübersetzung der durch die Huffman-Kodierung generierten Codes ermöglicht er die verlustfreie Wiederherstellung von Originaldaten. Seine Anwendungsbereiche sind vielfältig, von der Textkompression bis hin zur Bild- und Videokodierung. Trotz einiger Einschränkungen, wie der Notwendigkeit eines Huffman-Baumes und einer geringeren Effizienz bei gleichmäßig verteilten Daten, bleibt der Huffman-Decoder ein fundamentales Werkzeug in der digitalen Datenverarbeitung. Seine Fähigkeit, Speicherplatz zu sparen und Datenübertragungen zu beschleunigen, macht ihn zu einem unverzichtbaren Bestandteil moderner Informationstechnologie.
