Huffman decoding is a lossless data compression technique that efficiently restores compressed data to its original form.
Huffman Decoder: An Introduction to the Compression Technique
Huffman decoding is a widely used lossless data compression technique, first introduced by David A. Huffman in 1952. As an essential component of the broader Huffman coding algorithm, the decoder plays a crucial role in the efficient and seamless storage and transmission of digital information. In this article, we will explore the fundamentals of Huffman decoding, its advantages, and some real-world applications.
Understanding the Huffman Coding Algorithm
Before diving into the specifics of the Huffman decoder, it is important to understand the basics of the Huffman coding algorithm. The algorithm operates on a simple principle: it assigns shorter codes to more frequently occurring symbols and longer codes to less frequently occurring symbols. This variable-length prefix code technique ensures that no code is a prefix of another, allowing for unambiguous decoding.
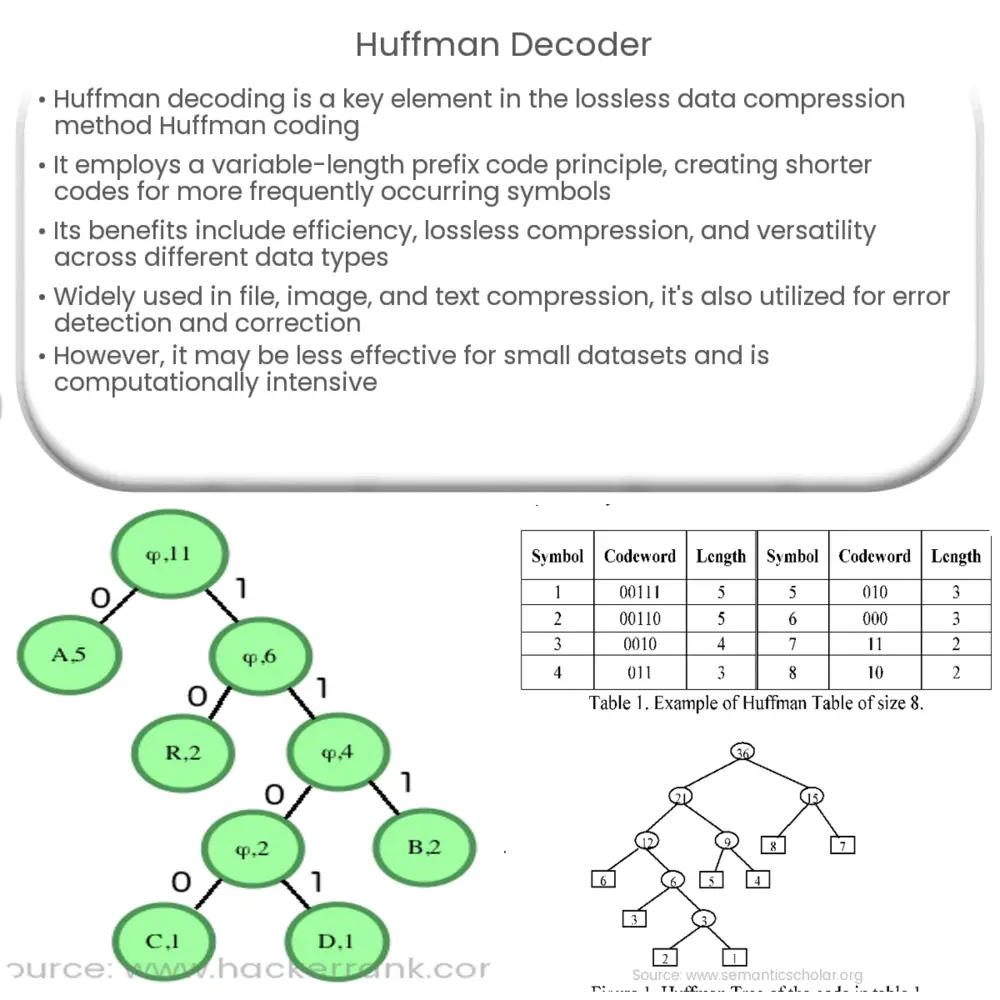
The Huffman coding algorithm uses a binary tree structure called the Huffman tree to determine the optimal code for each symbol. The tree is constructed by creating a node for each symbol and assigning it a weight equal to its frequency. These nodes are then arranged in a priority queue, with the lowest weights having the highest priority. The algorithm proceeds by repeatedly merging the two nodes with the lowest weights until a single tree remains.
Decompression with the Huffman Decoder
The Huffman decoder is the counterpart to the encoder, responsible for decompressing the compressed data back into its original form. The decoding process involves traversing the Huffman tree, which is typically reconstructed from the compressed data’s header. Beginning at the root node, the decoder follows the tree’s branches according to the binary code, with a ‘0’ leading to the left child and a ‘1’ leading to the right child. When a leaf node is reached, the corresponding symbol is emitted, and the traversal restarts from the root node. This process continues until the entire compressed bitstream has been decoded.
Advantages of Huffman Decoding
Huffman decoding offers several advantages over other lossless compression techniques, including:
- Efficiency: Huffman coding ensures optimal code assignments based on symbol frequency, resulting in an efficient compression of the data.
- Lossless: Since Huffman decoding is a lossless technique, the original data can be perfectly reconstructed without any loss of information.
- Widely applicable: The algorithm can be applied to various types of data, including text, images, and audio files, making it a versatile solution for many different applications.
In the next section, we will delve deeper into real-world applications of Huffman decoding and explore how this powerful technique continues to shape the digital landscape.
Real-World Applications of Huffman Decoding
Huffman decoding has found extensive use in various real-world applications, some of which include:
- File compression: Huffman coding is often used in popular lossless file compression algorithms, such as the DEFLATE algorithm used in the widely adopted gzip and zlib formats. These formats are employed in compressing web content, software distribution, and archiving files to save storage space and reduce transmission times.
- Image compression: The technique is also applied to lossless image compression, such as in the PNG format. By efficiently compressing the image data without loss of quality, Huffman decoding contributes to reduced file sizes, making it ideal for web use and conserving bandwidth.
- Text compression: Huffman decoding is used in various text compression applications, including those for natural language processing, where large volumes of text data need to be stored and transmitted efficiently.
- Error detection and correction: Huffman coding can be combined with error detection and correction techniques, such as Hamming codes, to improve the reliability of data transmission over noisy channels.
Challenges and Limitations
Despite its many advantages, Huffman decoding is not without its challenges and limitations:
- Non-optimal for small datasets: Huffman coding is most efficient when dealing with large datasets, where symbol frequencies can be accurately estimated. For small datasets, the algorithm may not produce optimal compression results.
- Static vs. dynamic coding: In static Huffman coding, a single code table is used for the entire dataset, which can be less efficient if the data’s symbol distribution changes significantly. Adaptive Huffman coding addresses this issue by dynamically updating the code table as the data is processed, at the cost of increased complexity.
- Computationally intensive: Building the Huffman tree and maintaining it during the decoding process can be computationally intensive, particularly for large datasets or when using adaptive coding techniques.
Conclusion
Huffman decoding is an integral part of the widely used Huffman coding algorithm, providing efficient lossless data compression across a variety of applications. With its numerous advantages, such as efficiency, lossless compression, and versatility, it has become a foundational technique in the digital world. While it has some limitations, ongoing research and improvements continue to enhance Huffman decoding’s performance, ensuring its continued relevance in the ever-evolving landscape of data storage and transmission.
