ハフマンデコーディングはデータ圧縮で使用されるアルゴリズムで、効率的なビット列復元と情報損失なしのデコードを実現します。
ハフマンデコーディングとは
ハフマンデコーディングは、データ圧縮における重要な手法の一つであり、特にエンタオプィ符号化の範疇に属しています。このアルゴリズムは、1952年にデビッド・ハフマンによって開発されました。ハフマンデコーダは、エンコードされた情報をもとに戻すデコーダーであり、ファイルやデータ伝送の圧縮に幅広く使用されています。
ハフマンデコーディングの原理
ハフマンデコーディングは、データを効率的に圧縮するために使用されるハフマン符号化の逆過程です。ハフマン符号化では、データを構成する各文字に、使用頻度に基づいて短いビット列を割り当てることで、全体のデータ量を減らします。より頻繁に使用される文字には短いコードを、希に使用される文字には長いコードを割り当てます。
このエンコーディングプロセスでは一意的なプレフィックスコードが生成されるため、これによって生じるビット列は、元のデータに戻るための明確な手掛かりを持ちます。つまり、ハフマンデコーダはエンコードされたデータやビット列を受け取り、それをハフマン木を使って元の文字列やデータに復元します。
ハフマンデコーディングのプロセス
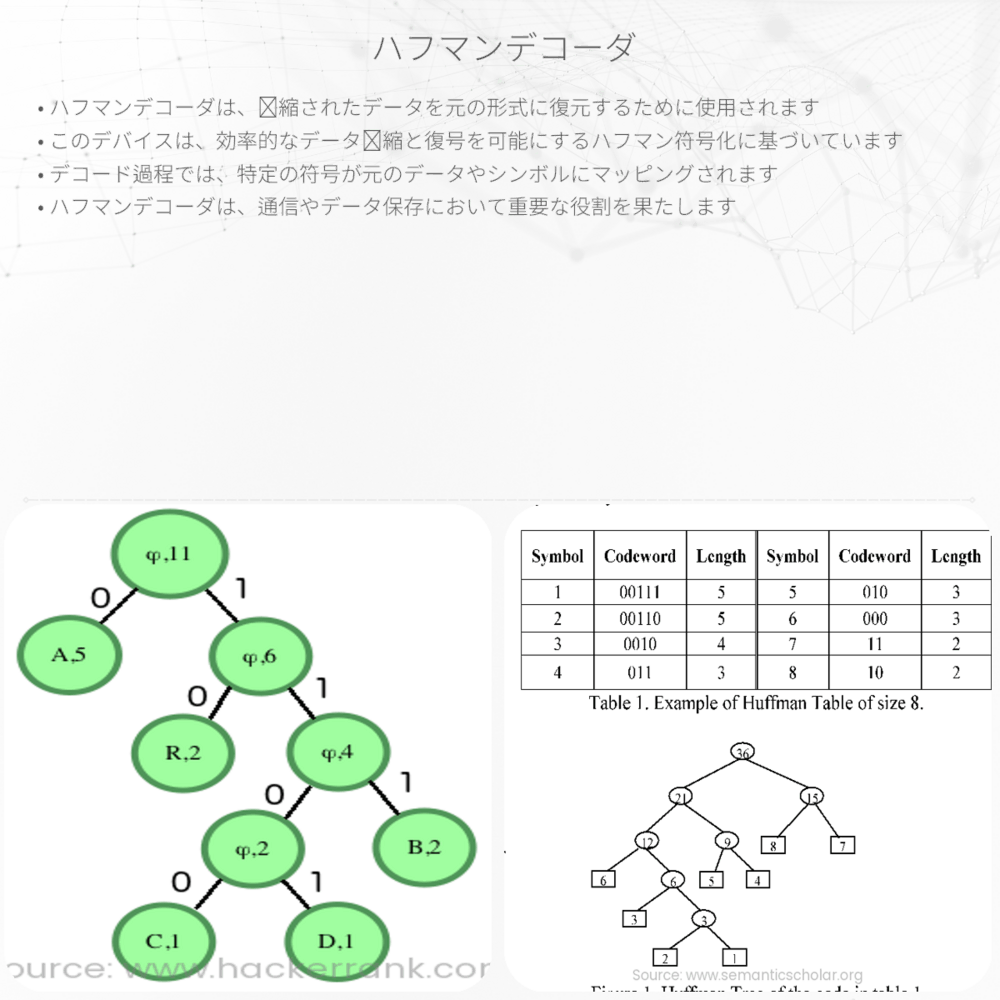
- まず、エンコーディング時に作成されたハフマン木を生成または入手します。これは、デコードを行うための”マップ”となります。
- エンコードされたデータ、すなわちビット列を入力として受け取ります。
- ビット列を先頭から順に読み、ハフマン木をたどります。枝をたどる過程で、’0’は左の子、’1’は右の子を意味します。
- 葉に到達すると、対応する文字に到達したことを意味し、これを出力します。
- 木の根に戻り、エンコードされたデータがなくなるまでこのプロセスを繰り返します。
ハフマンデコーディングの利点
ハフマンデコーディングは非常に効率的です。それは、エンコーディングプロセスにおいて生成されるコードが、元のデータをデコーディングするために必要なすべての情報を含んでいるからです。デコードされたデータはエンコードされる前の状態と完全に同じになり、情報の損失は一切ありません。
また、ハフマンデコーディングは、ビット列がそのままの順序で読まれるため、ストリーミングデータに対してリアルタイムで適応することが可能です。これにより、リアルタイム通信やストリーミング配信などの分野で有効に機能します。
結論
ハフマンデコーディングはデータ圧縮の分野において非常に重要なアルゴリズムです。その効率性と信頼性により、情報を小さなサイズで保存することが可能となり、データの送受信を迅速かつ正確に行うことができます。ハフマンデコーディングによるアプローチは、ディジタル時代においてますます重要となってきています。
